
Charity Donor Match
Project Summary
Background:
CharityML is a fictitious charity organization located in the heart of Silicon Valley that was established to provide financial support for people eager to learn machine learning. After nearly 32,000 letters were sent to people in the community, CharityML determined that every donation they received came from someone that was making more than $50,000 annually. To expand their potential donor base, CharityML has decided to send letters to residents of California, but to only those most likely to donate to the charity. With nearly 15 million working Californians, CharityML needs to build an algorithm to best identify potential donors and reduce overhead cost of sending mail.
Goal:
The goal is to evaluate and optimize several different supervised learners to determine which algorithm accurately predicts whether an individual makes more than $50,000. Understanding an individual’s income can help the non-profit better understand how large of a donation to request, or whether or not they should reach out to begin with. While it can be difficult to determine an individual’s general income bracket directly from public sources, I will infer this value from other publically available features.
Analysis:
This project notebook will walk through the data exploration, data pre-processing, feature selection, model training, tuning and evaluation steps. I will also discuss various choices made during this analysis.
Results:
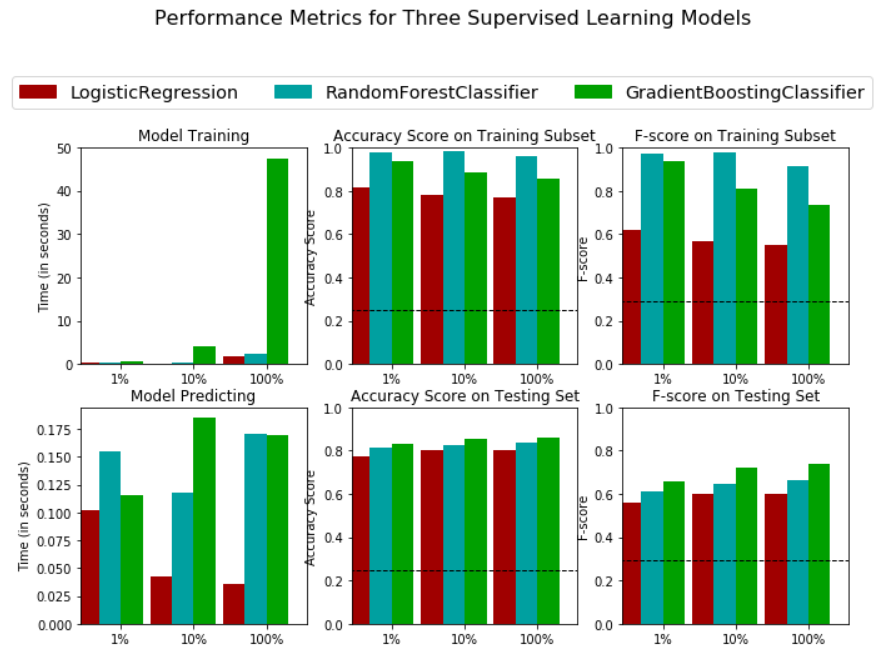
The final model (Gradient Boosting) achieves an accuracy of 87% and an f-score of 75% to determine if an individual is making more than $50,000 or not. The model also provides the top 5 features that are most important in predicting the income level.
Github:
The complete list of files and jypyter notebook can be found at Github