
Customer segmentation
Project Summary
Background:
In this project, I will work with real-life data from a company that performs mail-order sales in Germany. Their main question of interest is to identify facets of the population that are most likely to be purchasers of their products for a mailout campaign that will have the highest expected rate of returns. The data has been provided by Bertelsmann partners AZ Direct and Arvato Finance Solution. It contains two data sets. General population data and customer user base, both data sets having the same set of features. The features are in German language, so we have been provided with a data dictionary and also a feature summary file.
Goal:
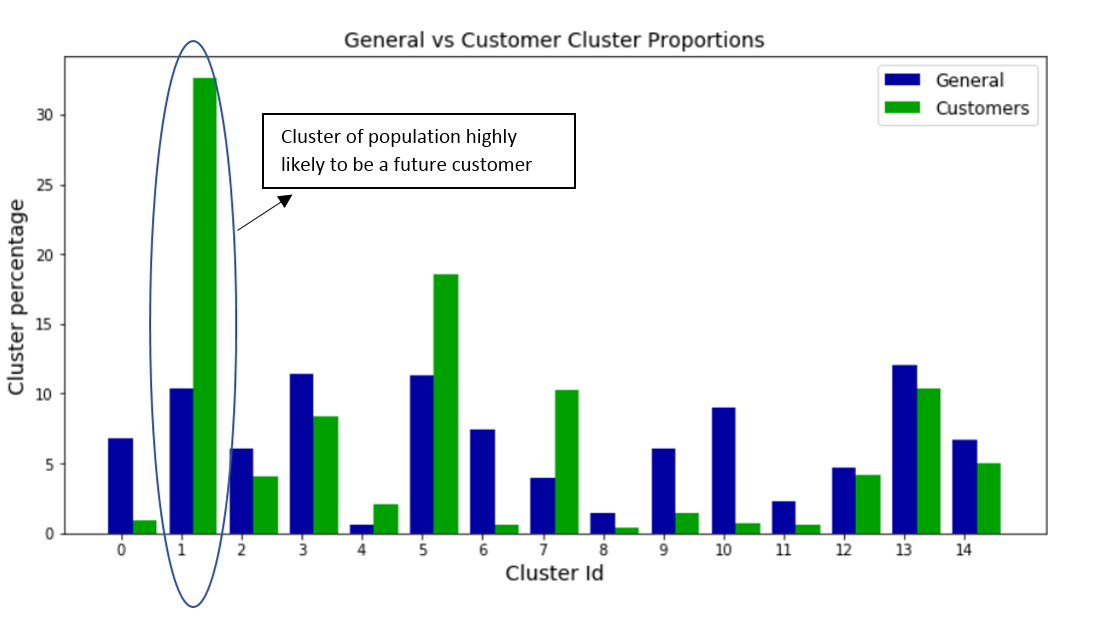
The goal is to identify segments of the population that form the core customer base for a mail-order sales company in Germany. I will use unsupervised learning techniques to organize the general population into clusters, then use those clusters to see which of them comprise the main user base for the company.
Analysis:
This project notebook will walk through the data exploration, data pre-processing, feature transformation, principal components analysis, clustering and comparison of the two population groups. I will also discuss various choices made during this analysis.
Results:
After clustering, the model identifies at least one cluster of general population which will be highly like to respond positively to a mail-order sales campaign. We can also identify at least one cluster which would be highly unlikely to respond to the mail-order sales campaign. This will significantly improve the expected rate of returns.
Github:
The complete list of files and jypyter notebook can be found at Github